

Developing a Traffic Sign Detector with limited amounts of training data
Aug 15, 2023
8 min read
Traffic signs are pivotal for the smooth functioning of roadways, ensuring that drivers and pedestrians have clear instructions to prevent accidents. In the realm of autonomous driving and intelligent transportation systems, the detection of these traffic signs becomes even more critical. One popular and effective method to detect traffic signs is through the use of Faster R-CNN.
However, in countries with limited access to datasets, developing robust machine learning models can be a challenge. With the right techniques and resources, it's entirely feasible. In this blog, we will explore how we can develop a traffic sign detector based in Hong Kong using Faster R-CNN under such constraints.
The Power of Faster R-CNN
Faster R-CNN is a deep learning architecture in object detection. R-CNN stands for Region-based Convolutional Networks, a type of deep learning model under the broader category of Convolutional Neural Networks (CNNs). These models excel at handling grid-like data such as images, consisting of layers like convolutional, activation, pooling, and fully connected layers. Their main strength is extracting crucial features from images for classification.
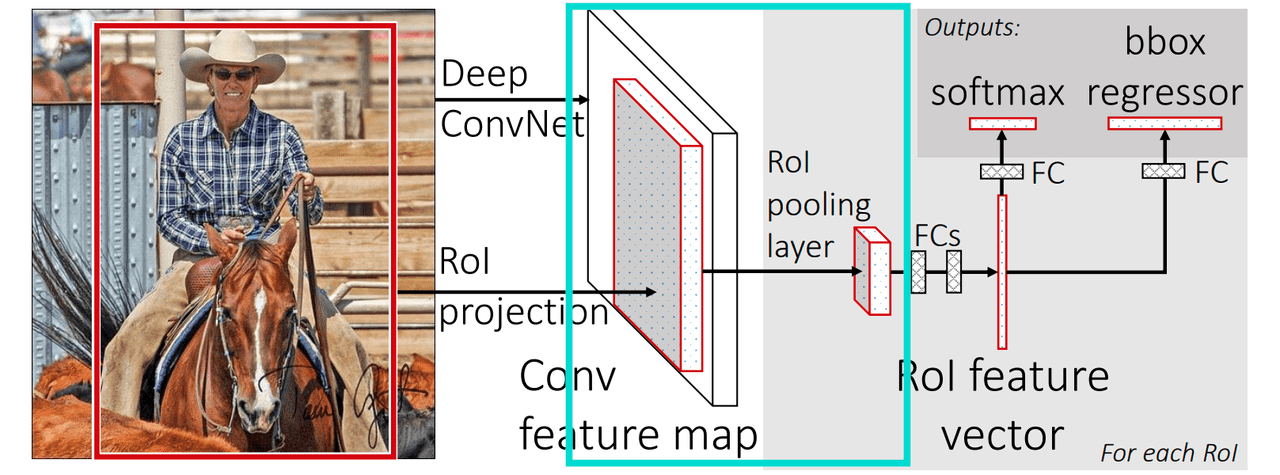
R-CNN models further boost the CNN's capability by pinpointing various object areas in pictures. A common method for object detection is to generate multiple regions, input them into the CNN, and then classify each. But this introduces challenges like efficiently managing regions of diverse sizes and smartly proposing regions without brute-force. Faster R-CNN offers solutions to these issues.
Fast R-CNN and its successors, including Faster R-CNN, use the Region of Interest (ROI) pooling technique to deal with differently sized and shaped region proposals. To classify these regions and predict their bounding boxes, they need to be of a consistent size. ROI pooling takes feature maps of these diverse-sized region proposals and converts them into uniform-sized feature maps, which are then sent to the subsequent layers. Essentially, it pulls out regional features from the larger image map without the need to re-process each region through the CNN.
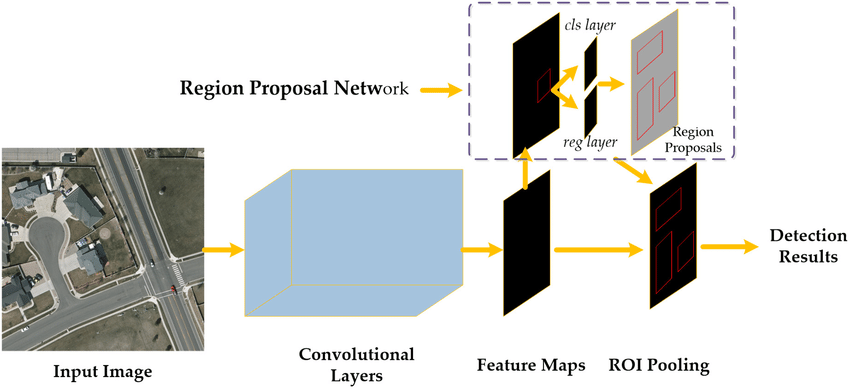
Why is Faster R-CNN "faster" than Fast R-CNN? The former melds the Fast R-CNN detector with a Region Proposal Network (RPN) to produce region proposals. The RPN's primary role is to churn out region proposals, or potential bounding boxes that may house objects. It's a comprehensive convolutional network that goes over the feature maps from the given image in a sliding window manner. At every step, it proposes multiple bounding boxes (termed anchors) of various sizes and shapes. These anchors are then optimized by predicting their likelihood of containing an object and adjusting their coordinates. This way, the RPN is trained to offer top-tier region proposals more inclined to encase the desired objects.
Data Collection from YouTube

One of the biggest challenges in countries with limited datasets is gathering and annotating data. We just downloaded some videos about driving experience in Hong Kong from Youtube. And extract the frames using the following command with FFmpeg. You can change the frame_rate to 3 such that each second in the video will generate only 3 images.
ffmpeg -i <input_file> -r <frame_rate> output_%05d.pngLabeling with LabelImg
Next, we make use of the LabelImg labeling tool. This tool facilitates the creation of a Docker platform where images can be uploaded for annotation. The resulting annotated dataset can then be exported in widely used formats for object detection. Remember to export the dataset in the COCO format. This format compatibility proves advantageous as it aligns seamlessly with the python library pycocotools that we intend to use later in our workflow.
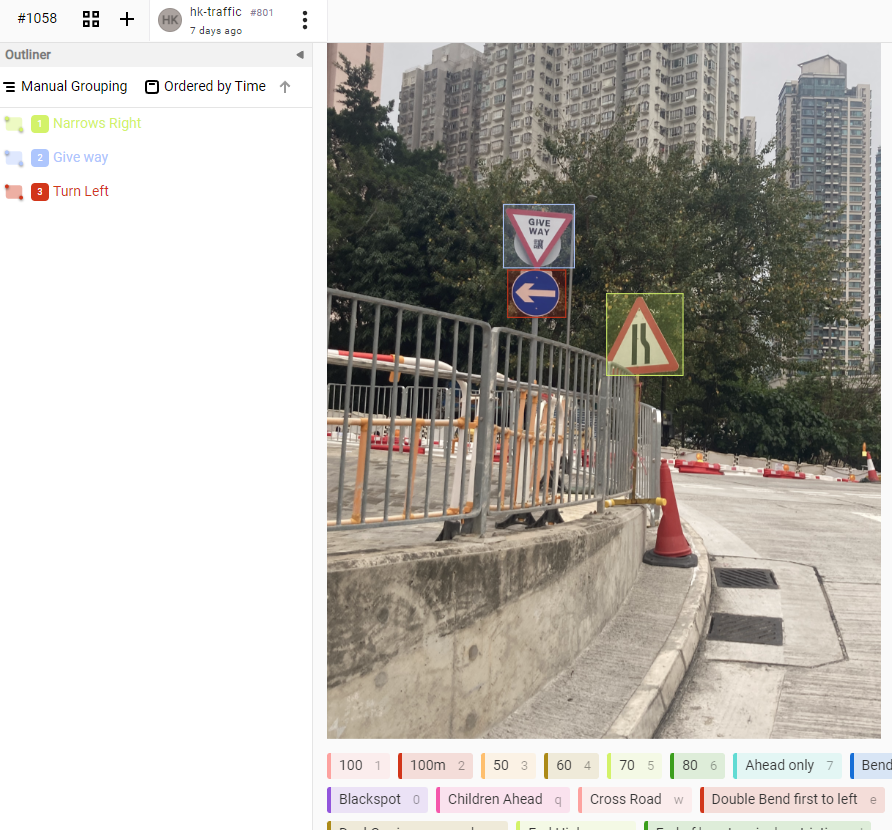
Since each image may contain multiple signs, we manually draw bounding boxes around each sign and assign corresponding class labels to them. It may takes few hours to label for about 800 images.
Data Augmentation
Getting our hands on a huge volume of training samples isn't always feasible. Imagine our plight when we have to manually curate a dataset for something intricate like road scene recognition. We'd have to drive under various conditions, perhaps rain or fog, just to capture a diverse range of images. This manual effort might still fall short of encapsulating all potential scenarios.
Enter image augmentation – our knight in shining armor! It's a nifty process where we tweak our existing images to create brand new training examples. Think of it as giving an image a little makeover - perhaps dimming the lights (adjusting brightness), giving it a little trim (cropping), or even showing its reflection (mirroring). These alterations work wonders in beefing up our dataset, combating overfitting, and boosting the efficacy of our neural networks, especially in visual tasks.
However, a word of caution: not all augmentations are a good fit for every scenario. Take this for instance - flipping an image horizontally might lead our model astray when it comes across direction-specific traffic signs. The trick is to strike a balance. We need to introduce enough variability without compromising the image's essence. Below is an example of transformations applied to the original image to generate a new training sample with Albumentations.

Implementation
Importing Data from COCO Dataset:
The COCO (Common Objects in Context) dataset is one of the most popular datasets for object detection, segmentation, and captioning. To work with it in Python, we often make use of the pycocotools library, which provides a set of utilities for the dataset.
In the code you provided, the TrafficSignDataset class is created to handle data loading from the COCO dataset:
pythonclass TrafficSignDataset(torch.utils.data.Dataset): def __init__(self, root, annotation, transforms=None): self.root = root self.transforms = transforms self.coco = COCO(annotation) self.index_map = {i: key for i, key in enumerate(self.coco.imgToAnns.keys())} self.label_map = self.get_label_map()
Here, annotation is the path to the COCO annotations file (usually in JSON format). This allows you to access images, their annotations, and related metadata using the COCO API.
Data Augmentation using Albumentations:
Albumentations is a fast image augmentation library that offers a diverse set of augmentation techniques. It's widely used because of its speed and efficiency.
In the get_transform function:
pythondef get_transform(train=True): if train: return A.Compose([ A.RandomBrightnessContrast(p=0.2), A.ColorJitter(p=0.1), ToTensorV2() ], bbox_params=A.BboxParams(format='coco', label_fields=['class_labels'])) else: return A.Compose([ ToTensorV2() ], bbox_params=A.BboxParams(format='coco', label_fields=['class_labels']))
The function returns a set of transformations that will be applied to images. If the data is for training (train=True), augmentations like RandomBrightnessContrast and ColorJitter are applied. These augmentations introduce random variations in brightness and color, respectively.
The bbox_params argument ensures that the bounding boxes are also transformed appropriately when the image is augmented.
Using Pre-trained Faster R-CNN models:
Torchvision, a library by PyTorch, offers a variety of pre-trained models including Faster R-CNN. Using these pre-trained models is advantageous because they are already trained on large datasets, allowing for transfer learning where the pre-trained weights act as a solid starting point.
pythonmodel = torchvision.models.detection.fasterrcnn_resnet50_fpn_v2(weights=FasterRCNN_ResNet50_FPN_V2_Weights.DEFAULT)
Here, fasterrcnn_resnet50_fpn_v2 is used, which is a Faster R-CNN model with a ResNet-50 backbone and Feature Pyramid Network (FPN) for multi-scale object detection. By default, it's loaded with weights pre-trained on the COCO dataset.
To adapt the pre-trained model to a new task (with a different number of classes):
pythonnum_classes = len(full_dataset.coco.getCatIds())in_features = model.roi_heads.box_predictor.cls_score.in_featuresmodel.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
The code adjusts the final layer (box_predictor) of the model to predict the appropriate number of classes for the new dataset. You use other Faster-RCNN models in torchvision.models.detection.faster_rcnn.

Evaluation
The MobileNet and ResNet50 architectures were both trained over 50 epochs, utilizing the Adam optimizer set at a learning rate of 0.01. For both architectures, we conducted trials under two conditions: one with data augmentation and another without. This was done to gauge the influence of augmentation techniques on the models' effectiveness. Post-training, we evaluated the models on a subset comprising 20% of the entire dataset, using the mean Average Precision (mAP) as our performance metric.
Here's a breakdown of the mAP results for the evaluated models:
- Resnet50 (with augmentations): 0.3996
- Resnet50 (without augmentations): 0.3488
- Mobilenet (with augmentations): 0.2238
- Mobilenet (without augmentations): 0.1900
From the data, it's clear that the ResNet50 model, when combined with data augmentations, surpasses the performance of the MobileNet model, registering an mAP of 0.3996 against 0.2238 from MobileNet. Moreover, it's noteworthy that the addition of data augmentation procedures enhances the efficacy of both models, leading to elevated mAP values.
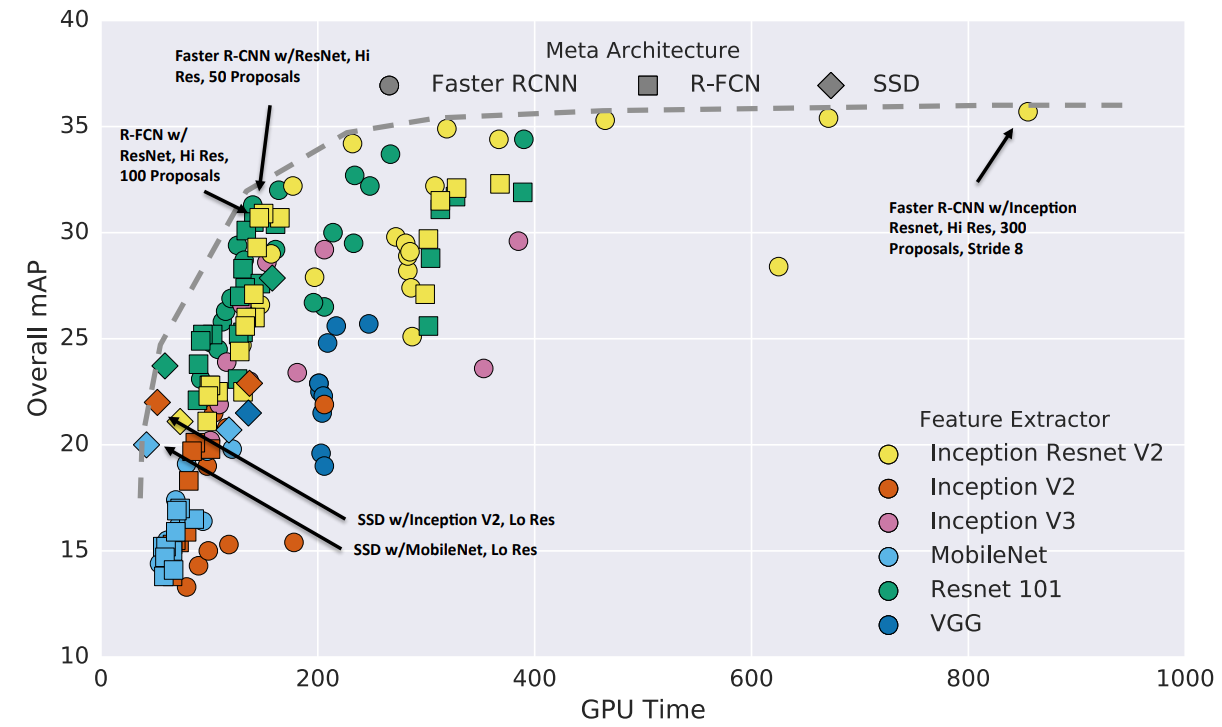
The outcomes of our experiments resonate with the observations outlined in the paper "Speed/accuracy trade-offs for modern convolutional object detectors." This research similarly illustrated that MobileNet doesn't measure up to the accuracy levels of the ResNet model. While the paper highlights that the Inception-ResNet model stands out in terms of precision, it demands considerably higher GPU resources, rendering it less optimal for real-time predictions. For a judicious blend of accuracy and computational resource conservation, we've opted for the ResNet50 model for our real-time showcase, since it offers an equitable compromise between efficiency and resource consumption.
Summary
- Data Source: Utilizing
FFMpegto extract frames from YouTube videos - Labeling:
LabelImgprovides a user-friendly interface for annotating the extracted frames, further enhancing our dataset's richness. - Data Augmentation: Through
Albumentations, we can execute efficient and diverse data augmentations, significantly improving the model's ability to generalize across varied scenarios. - Transfer Learning: Leveraging
torchvision's pre-trained Faster R-CNN models, we find a beneficial starting point that not only expedites training but also frequently results in superior model performance.
Developing a traffic sign detector in a country with limited training data may seem daunting, but with tools, innovative data collection methods, and transfer learning, it's entirely achievable. The procedure can be generally applied to any object detection tasks, leveraging these tools and strategies can significantly streamline the process and boost performance.
You can access the complete code in this repo.
 shingyipcheung
shingyipcheung